TL;DR
本文是LinkedIn发表在CIKM 2020上的文章,主要内容是基于曝光行为来做Pacing,控制预算消耗,帮助广告主触达更广泛的人群。
问题背景
LinkedIn的工作搜索和推荐服务的目标是帮助LinkedIn会员寻找下一份好工作,会基于求职人员的兴趣和技能推荐工作机会,同时求职者也可以主动搜索相关工作机会。向求职者推荐的工作大部分都是会基于其与求职者对的相关性进行推荐,同时LinkedIn也支持广告,招聘方可以通过设置一笔预算来获得更靠前的展示位。如何排序以及何时展示的决策机制,我们称为工作求职市场机制(Jobs Marketplace)。
Jobs Marketplace的目标是将LinkedIn会员匹配给招聘广告,使得招聘方的ROI有保证(平均每次点击和每次申请所需要花的钱)同时展示给求职者更加匹配的工作机会。这些是通过一价竞价机制所实现,每一个招聘广告都会设置一个出价(bid),代表了当前会员的价值,其依赖于匹配程度以及该招聘广告的剩余预算。因为需要考虑匹配程度,所以按照点击来进行付费,当一个招聘广告拥有更多的需求时,通过点击收费会更容易消耗其预算。
均匀地或是根据预设计划来花费每日预算的能力会变得极其重要,因为:
- 避免过高的出价可以合理消耗预算,参与更多次数的竞价,进而触达更广泛的候选人群。
- 不同的预算计划可以满足广告主不同的目标诉求
- 广告竞价的竞争会更加充分
Pacing算法是指进行预算消耗控制的方法,其输出一般是一个平滑分(pacing score),用于控制预算消耗速度。平滑分的计算方式一般会依赖于当前已经消耗的金额,但这样做会产生以下问题:
- 点击事件十分稀疏而且存在噪声
- 点击事件会导致“尖刺”行为的出现,比如一个招聘广告在第一个小时并没有任何点击,此时pacing算法会认为这个招聘广告无法花掉预算,进而增加出价帮它排在更靠前的位置,在下一次点击时,就会花费更多的钱。
解决方案
简化版的架构如下图所示:
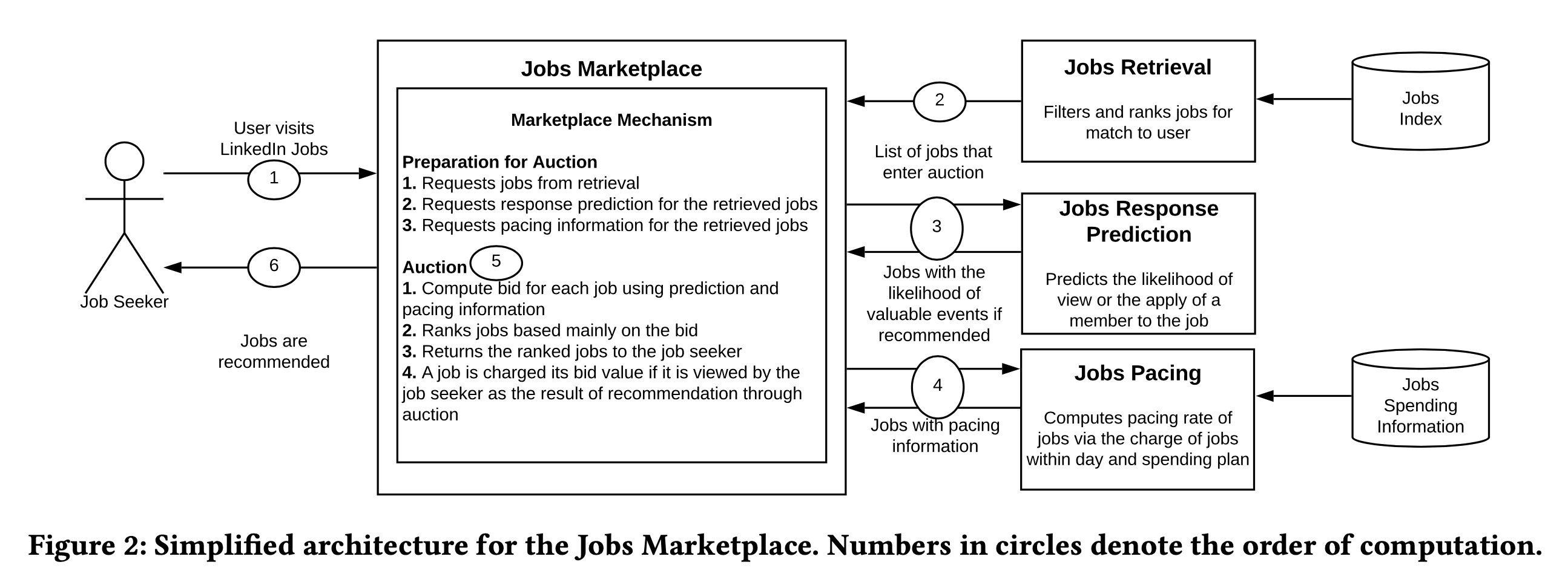
主要分为6个阶段:
- 用户访问页面
- 招聘广告召回,过滤和排序,选出更匹配的候选集合
- 模型打分,计算用户点击以及后续转化的概率
- 平滑,根据实时花费和预设消耗计划返回平滑分
- 根据预测概率和平滑分,进行竞价
- 将竞价胜出的招聘广告返回(可以返回多个)
其中平滑分:
\[ \Psi_t(\text{job}_i)=f( S_{a,t'\rightarrow t}, S_{p,t'\rightarrow t}, \Psi_{t-1}, \text{job}_i ) \] 其中\(\Psi_t(\text{job}_i)\)为广告\(i\)在\(t\)时刻的平滑分,\(S_{a,t'\rightarrow t}\)表示从\(t'\)到\(t\)时间内实际消耗,\(S_{p,t'\rightarrow t}\)为计划消耗。这样的形式化定义有几点需要注意的:
- \(t'\)可以为0也可以为任意时刻,我们关心的是任意时间区间上平滑问题
- \(\Psi_{t-1}\)也是输入,前一时刻的平滑分也会影响当前平滑分的计算
- \(\text{job}_i\)相关信息,不同招聘可能会有不同的流量结构,所以需要考虑job相关信息
处于商业考虑,此处不说明函数\(f\)的细节,整体上满足如下关系: \[ \begin{aligned} \frac{S_{a,t'\rightarrow t}}{S_{p,t'\rightarrow t}} < 1 && \Longrightarrow && \Psi_t >\Psi_{t=1}\\ \frac{S_{a,t'\rightarrow t}}{S_{p,t'\rightarrow t}} > 1 && \Longrightarrow && \Psi_t <\Psi_{t=1}\\ \end{aligned} \] 如果消耗超出计划了,平滑分降低,反之平滑分增大。
在竞价阶段,排序分为: \[ S(\text{job}_i, \text{job-seeker}_j) = \text{pCTR} \cdot \beta(\Psi(\text{job}_i)) +\Omega(\text{pApply},\cdots) \] 其中\(\text{pCTR}\)和\(\text{pApply}\)是模型的预估值,为点击的概率和申请的概率,\(\Omega\)主要是为了考虑求职者申请工作的概率,类似后转化链路的质量分,\(\beta\)是出价函数,其输入为平滑分\(\Psi\),具体函数细节不方便展示,但满足单调性。
由于是一价竞价、点击扣费,点击行为的噪声和稀疏会导致pacing算法不稳定。为了解决这个问题,我们提出基于曝光数据的平滑算法,用期望消耗来替代实际消耗,\(\hat{C}_{\text{auction}_i,\text{job}_j}=\text{pCTR}\cdot \beta\),累计消耗为\(\hat{C}_{\text{job}_j}=\sum_i \hat{C}_{\text{auction}_i,\text{job}_j}\)。
因为我们希望使用点击率来做平滑算法,所以需要对点击概率做校准。点击率的差异主要是位置的偏差,在推荐时我们并不知道最终广告会被排在什么样的位置,一般的做法是所有广告在计算点击率时都用默认的值(比如都设置为第一位),所以我们采用后置校准的方式。
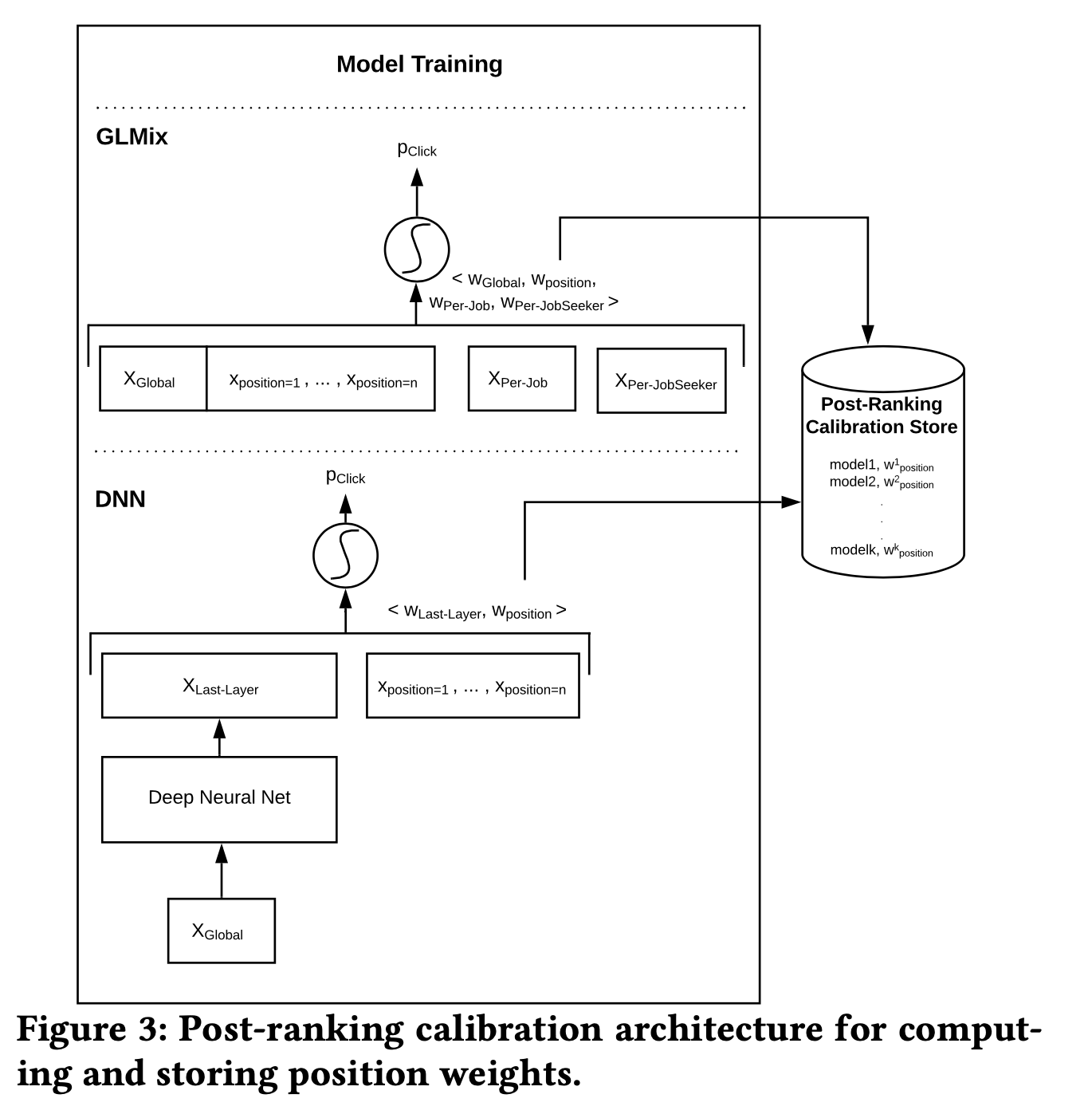
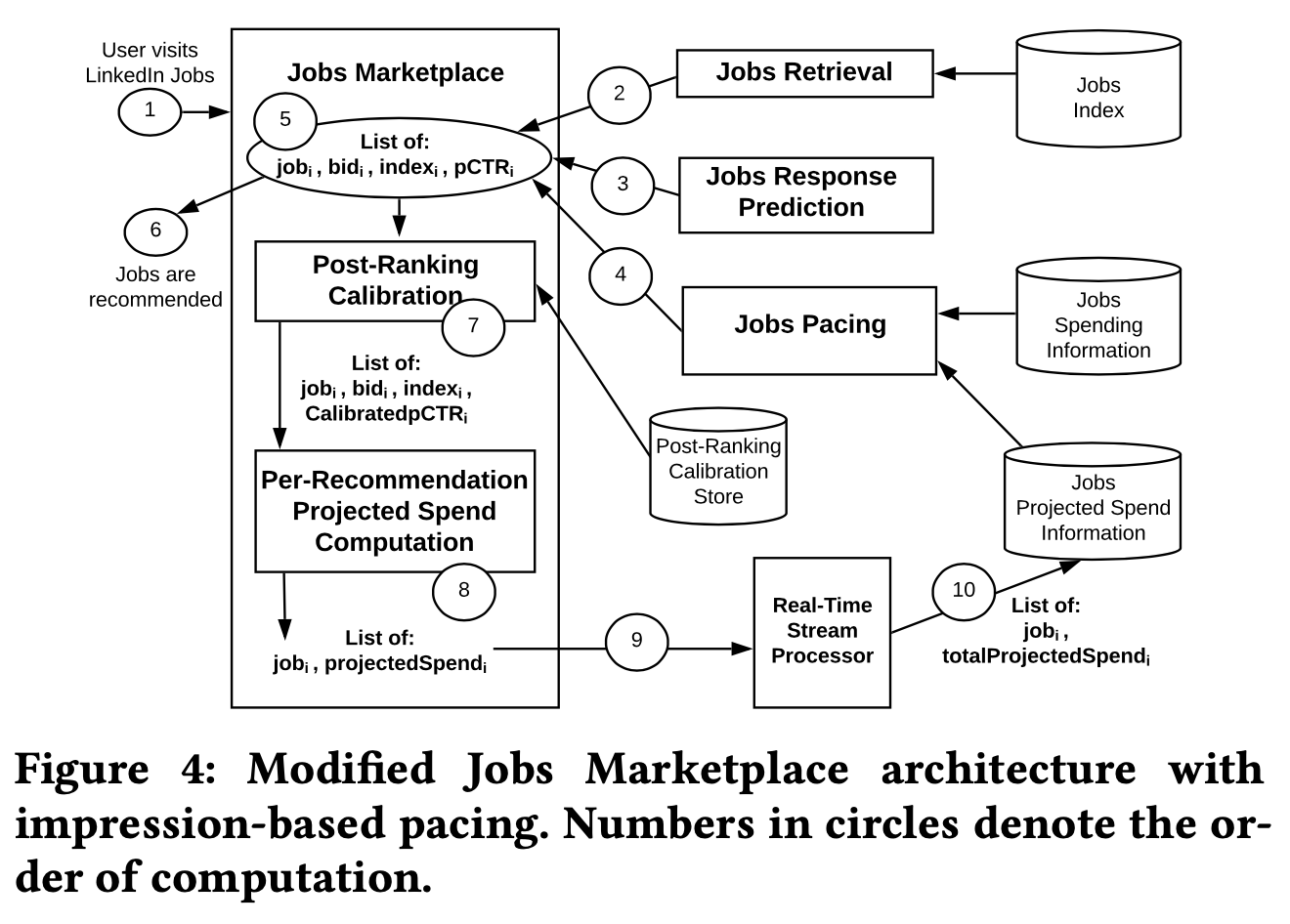
在计算\(\text{pCTR}\)时,用默认位置信息,进行竞价排序、展示后,重新计算校准后的值 \[ \text{pCTR}_\text{calibrated}=\sigma(X_\text{position}\cdot w_\text{position} +\sigma^{-1}(\text{pCTR})) \] 在得到校准后的值后,会用于计算实时期望消耗,然后和实际消耗一起考虑,产出平滑分

- 其中\(\alpha\)用于控制预算消耗量,一般\(\alpha\leq 1\),期望花费只能消耗掉整体预算的一部分
- 如果点击花费超过期望花费,此时以点击花费为准
- 如果点击花费为0,说明此时没有点击发生,用期望点击消耗为主,用\(\gamma\)来限制上限(如果\(\text{pCTR}\)高估严重,ceilProjectedCharge会非常高,但是实际消耗为0,如果直接用ceilProjectedCharge会拉低出价,所以用\(\gamma\)限制这个偏差程度)
- 如果真实点击消耗不为0,且小于期望值,此时用期望点击消耗为主,用\(\zeta\)限制这个差异的上限(同理,避免\(\text{pCTR}\)高估严重,所以限制了和实际消耗的差异)
线上尝试后,最终\(\alpha=0.7\),\(\gamma=0.3\),\(\zeta=1.3\)。
实验效果
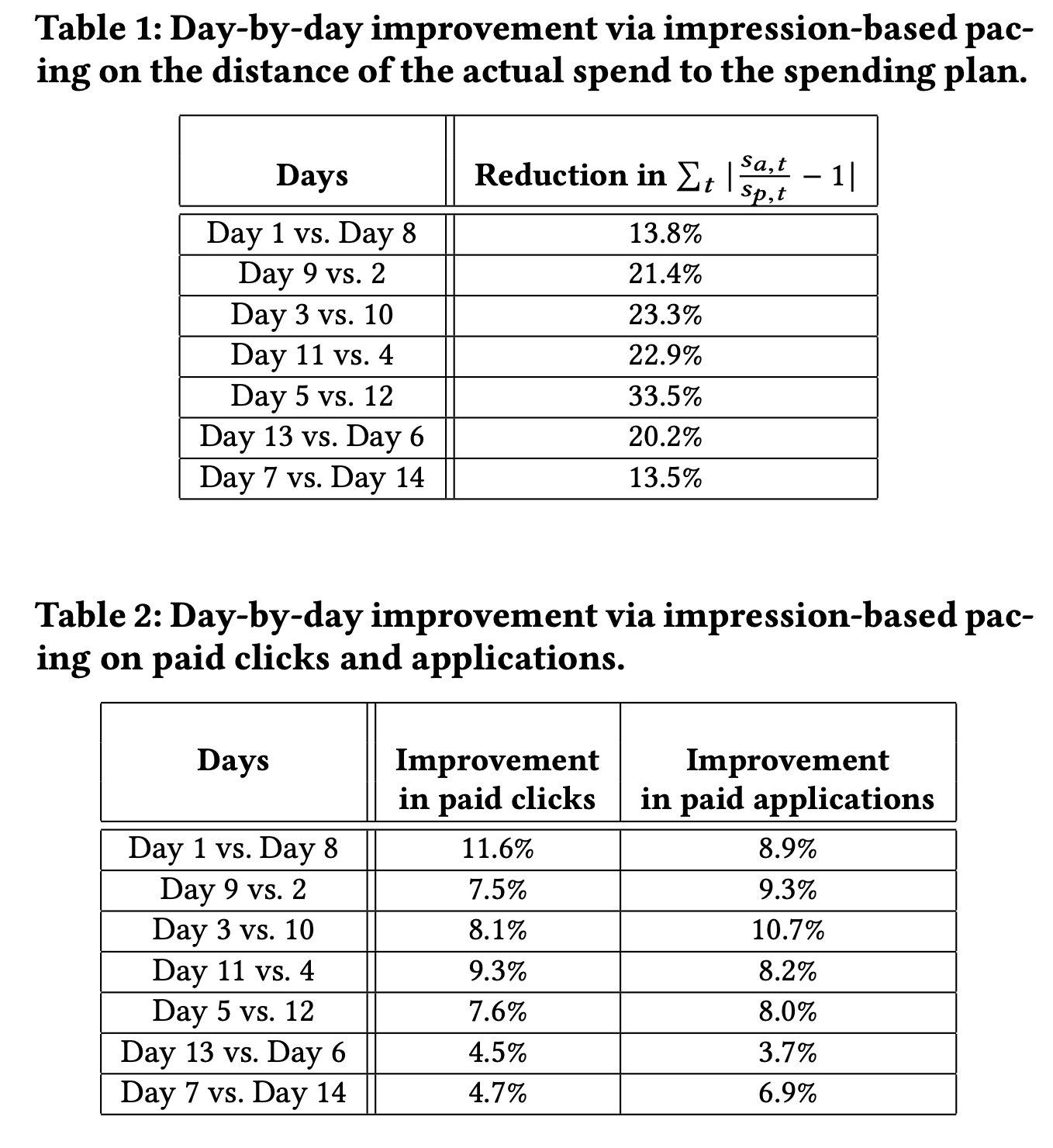
实验方式为天轮转,2周之后得到最终的对比结果(也是之前LinkedIn Pacing实验的评估方式)
总结
文中写了一种基于曝光数据的Pacing算法,核心思想就是用期望成本替代实际成本,并对pCTR的预估做校准。
这种方式应该已经是很通用的方式了(调控系统中,用模型期望值代替实际值),创新性欠佳,更多的是把已经证实有效的东西写出来。
实验方面做的很单薄,并没有从离线数据中证明校准的有效性,位置偏差对于最终Pacing结果的影响是有待商榷的。